Skylakeファーストインプレッション
2015/8/5に開発コードSkylakeで知られていたIntelの新CPUが発売されました。私も早速動かしていますが大変よい結果を得ています。今回は主に各所で公開されている情報等から従来のマイクロアーキテクチャとの比較を見てみます。
フロントエンド
とりあえず4wayのままのようです。フェッチ帯域やMacroOps Fusion等はまだ確認していません。あんまり変わっていない気がします。
実行ユニット
instlatx64の結果がアップロードされています。
主にFPU周りの変更が目立ちます。私が使う上で気になったところを挙げます。
- div/sqrtのスループットが劇的に向上した。ついでにrcpps/rsqrtpsも高速化している。
- blendvのスループットがHaswell/Broadwellの2から1に向上した。SandyBridge/IvyBridgeと同等に戻ったことになる。
- port0/1のほとんどの命令のレイテンシが4になった。fma, mul, add/sub, cmp, min/maxなど。cvt系命令は128bitオペランドでレイテンシ2から5になっている
- add/subがport0/1両方で発行できるようになった
- fpの論理命令(addpd等)がスループット1/3で実行できるようになった
gather系命令は高速化されているはずですがまだ確認していません。128bit境界をまたぐ命令のレイテンシは3のままでした。
port0/1のレイテンシを4に統一したのは、スケジューラやデータパスの簡素化や実装によってはPRFのwriteポート数の削減等が理由として考えられます。fmaのレイテンシが5から4に改善したのはその効果かもしれません。cvt系命令はもともと演算ユニットの丸めステージのみを用いていたと考えられるので従来のport0/1でレイテンシ1+シャッフルがport5でレイテンシ1は妥当で、今回の4+1=5は無駄に遅延を挿入していることになります。
cvt系命令のレイテンシの増加とdivpdの高速化から、特別にスループットを重視する場合を除いて、doubleではrcppsからのニュートン法による収束計算は使いどころがかなり微妙になりました。AVX512ではvrcp14pdがでるのでまた変わりますが。
従来は計算ツリーによってはfmaよりもmulとaddの組み合わせの方がレイテンシが小さくなる場合があったのですが、fmaとadd/subのレイテンシが同じになったので常にfmaでよくなりました。頭の悪いコンパイラにやさしくなりました。add/subは無駄に遅延を挿入しているので気分的にももったいないです。
hsw/brwではfmaの方がadd/subよりもスループットが高かったのでadd/subの代わりに1.0を掛けてfmaした方が速い場合がありましたが、何も考えずにadd/subすればよくなりました。一方でadd/subのレイテンシが4でスループット1/2になったので典型的な総和を取るケースでは8並列にする必要があります。
fp版の論理命令はPenrynまではIntドメインで実行されていてport0/1/5でdispatchできたのですが、NehalemからはFPドメインに別に実行ユニットが設けられてドメイン間をまたぐ際のレイテンシがかからないようになった一方で、port5のみでの実行になっていました。Skylakeではスループット1/3になっており、レイテンシも1なので、ほかの命令のレイテンシとの整合性を考えると、FPドメインからはなくなった可能性があります。これが正しいとすると、FPとIntで行き来するのでレイテンシが追加されます。符号反転等ににxorを使うのは不利な場合が出てきます。まぁ最近はfmaの符号組み合わせが豊富なのであんまり使わないんですが。
メモリシステム
特にL2/L3の帯域が向上したと複数のレビューに出ています。
「Skylake-K」とはいかなるCPUなのか。「Core i7-6700K」ベンチマークで新世代マイクロアーキテクチャの実態を探る - 4Gamer.net
hsw/brwでは名目の帯域はL2で64B/cycle、L3で32B/cycleとされていました。
「Haswell」って何だ? 第4世代Coreプロセッサが採用するアーキテクチャのポイントを一気に押さえよう - 4Gamer.net
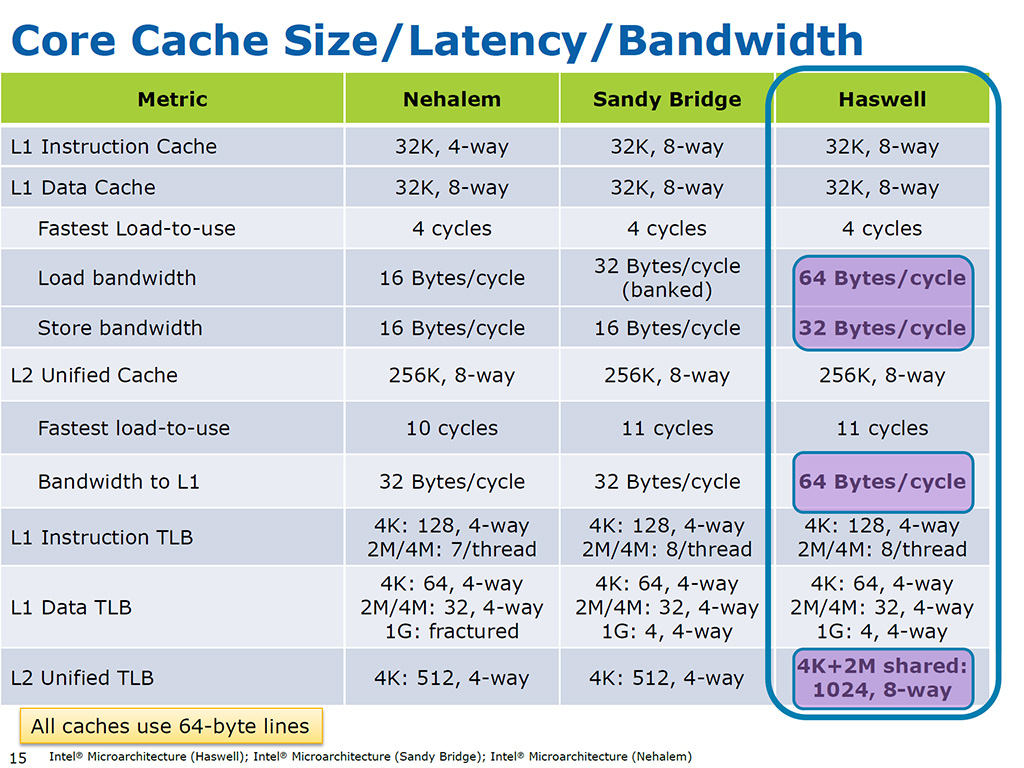
実測ではこの半分程度しかでておらず、いろいろなアクセスパターンを調べましたが、私には原因はわかりませんでした。Skylakeでは従来あった何らかのボトルネックが解消されて名目のピーク帯域に近づいたと考えるべきだと思います。
測定はしていませんが、いくつかのベンチマーク結果を見ると、ストアフォワードが改善している気がします。
FPU周りの変更やキャッシュ帯域の改善はAVX512への布石と考えたいですね。
マイクロアーキテクチャに関しては今度のIDFでなんらか解説があると思います。
ダイ写真が出れば512bit演算器をもっているがdisableされているかどうかがわかるかもしれません。最近のCPUの規模からすると演算器はゴミみたいに小さいので判別は難しいと思いますが。
追記 2015/08/23
L3のロード帯域は名目でhsw/brwの倍の64B/cycleになっているようです。さらにシングルスレッドでもL1~L3までほぼ名目ピークに近いロード帯域を発揮できるようで驚異的な向上です。Haswell-EX以降のリング+LLCに関してはまたどこかで書きたいと思います。