Skylakeのデコード帯域の謎
【後藤弘茂のWeekly海外ニュース】Skylakeアーキテクチャの謎 その2 〜5命令デコーダと6命令uOPキャッシュ - PC Watch
上の記事では、Skylakeのデコーダは5wayに、uOP$の帯域は6uOPs/cycleになったとされています。IDFのスライドでも "Wider instruction supply with deeper buffers"と書かれている箇所があります。ただ、以前も書いたように私はuOP$やLSBの範囲ですら4uOPs/cycleを超えるパターンを見つけられていません。
- nop(0x90) は特別扱いでuOPを生成しませんが、LSB/uOP$/L1の範囲で4OPs/cycleでした。
- xorはレジスタリネーミングでuOPが消滅しますが、これも4OPs/cycleでした。
- xorは実行ユニットで実行される場合ポート0156でイシューできますが、これが制限となっている可能性があるので、xorを4命令+ロード1命令やxorを3命令+ロード2命令を試してみましたが、これも4OPs/cycleでした。ロードはGPでもFPでも同じでした。
- ライトバックの帯域制限がある可能性を考慮してxorを4命令+ストア1命令にしてみましたが、これも4OPs/cycleでした。
これらの値はHaswellと同じものです。
後藤氏の話はかなり具体的なもので真実味がありますが、実際の測定とは食い違います。仮に4uOP/cycleを超えられるとしても、制限は厳しそうですね。
また、分岐が少なくIPCを出しやすい数値計算系コードでは1命令のサイズが大きいため、16B/cycleのフェッチ帯域では5wayのデコーダを活用するのは困難です。
追記10/8
6uOPsというと、uOP$のエントリあたりのuOP数ですよね。だとすれば6uOPs/cycleというのは説明がついた気がします。ただしSkylakeで6uOPs/cycleになったわけではありません。Haswellでは1エントリに格納できるのは32Byteブロック内の連続命令列でしたがこれが64Byteに拡張されたという仮説です。もちろんこの場合もLSB以降は4uOPs/cycleにとどまり6uOPs/cycleでスケジューリングや実行ができるわけではありません。6uOPsの帯域が生かされるのはエントリに少ない命令数しか入っていない場合と分岐の場合です(トレースキャッシュではないので)。64Byteになれば前者のケースが緩和されます。
Xeon E3-1500 v5はAVX512をサポートしない
Xeon E3-1500 v5が正式に発表されていました。
インテル、ノートPC向け「Xeon Processor E3-1500M v5」ファミリを発表--秋から提供開始 - CNET Japan
ARKにも情報が登録されていますが、
ARK | Intel® Xeon® Processor E3-1535M v5 (8M Cache, 2.90 GHz)
命令セット拡張 SSE4.1/4.2, AVX 2.0
Core i3/i5/i7版のSkylakeと同じものです。
ダイ的にはAVX512の演算器が実装されていてCore i版はDisableされていることを期待していましたが、そんなことはないようです。従来のXeonはCPUコアの設計はCore iとほぼ同じでキャッシュやリングのみを別設計としていましたが、Core iとダイを共有するXeon E3と、2ソケット版以上のXeonとではコアの設計を少なくともFPUに関しては大きく変えてくることになります。
AVX512が使えるCPUはKnights Landingを除くと、2016末から2017頭と予想されるSkylake Xeon E5が初になります。一方で、デスクトップ・ノート向けのラインナップは最近14nmでKabylakeが間に入るという情報が流れています。
北森瓦版 - 緩やかになる“Tick-Tock”―“Kaby Lake”は2016年後半になるらしい
KabylakeがAVX512をサポートするなら2016年中に使えることになります。Skylake Xeon用にAVX512付きで物理設計が進んでいるなら、14nmでAVX512付きのCore iを派生させることは可能だと思います。AVX512使用時はクロックが低下する仕様にになると思われますが、使う人は限られているので通常問題にはならないでしょう。
ただし、sdeのオプションには今のところ(ver 7.21 2015/4/1版)Kabylakeのオプションは出現していません。
Intel® Software Development Emulator | Intel® Developer Zone
Nehalem以降のIntelは世代毎に2倍という狂ったようなペースでFPUのピーク性能をあげてきていますが、今回で鈍化することになります。まぁ、Pentium 4から数えると、nhmは一回休みだったわけでそういう時もあっていいのかなと思います。個人的な感覚だと、Haswellは実行効率が落ち気味だったのがsklでsnbと同等以上に戻った感じです。
SkylakeのIDF発表
IDF2015でIntelからSkylakeのマイクロアーキテクチャについての解説がありました。日本語ではPCWatchで後藤氏が解説記事を出しています。
【後藤弘茂のWeekly海外ニュース】Intelの次世代マイクロアーキテクチャ「Skylake」 - PC Watch
まずLLCの配置ですが、私は理由が想像付かなかったのですが、後藤氏によると、
Skylakeのダイ(半導体本体)を見ると、CPUコアの周囲をぐるっとLL(Last Level)キャッシュSRAMが囲っている。通常のCPUコアレイアウトでは、見慣れないSRAMの配置だ。これは、CPUコアの熱を効率的に分散するための工夫だと見られる。
とのことで、なるほど感があります。
ついでに私もひとつ理由を思いついたのですが、現在のリングバスを2次元メッシュや2次元トーラスに拡張するのに上下方向の配線を通すのに使えそうですね。マルチソケットのSkylake Xeonはおそらく32コア程度まで拡張すると思われるので、リングは多重化してスヌープフィルタをいれても共有LLCでまともに性能の出せる限界を超えています。

フロントエンド
"Wider instruction supply with deeper buffers"となっています。L1I$帯域は16B/cycleのままなので、これはuOP$かLSBのことだと考えられますが、4wayから増えた証拠は見つけられていません。
"Faster prefetch"ですが、L2$, L3$からのフェッチ帯域は実測で増えているようなので、このことだと思われます。
スケジューラ
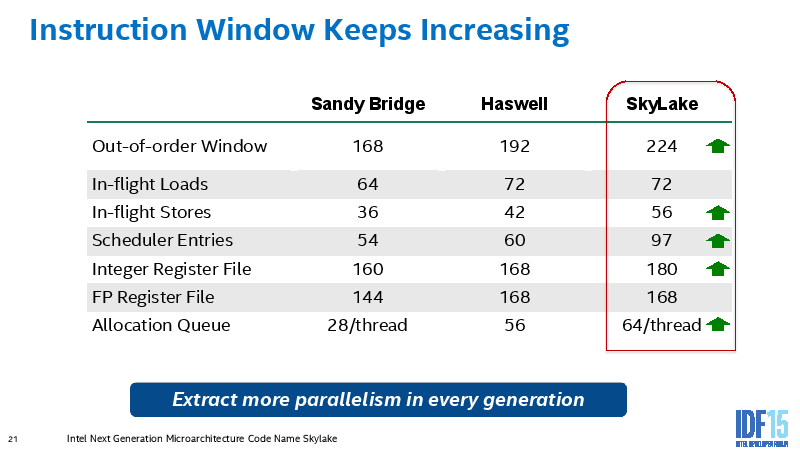
RSのエントリ数が60->97と鬼のように増えています。way数を増やすと3乗でリソース≒消費電力が増えますが、エントリ数は線形にしか影響しないのでエントリ数を増やすしか道がないのです。ただ、常に全力で埋めているわけではないのではないかと推測します。
これだけエントリ数が増えると演算器レイテンシ隠蔽のためのループアンローリングは完全に過去のものですね。まぁ今も大抵必要ないですが。
97あれば命令密度によってはL3ミスも隠蔽できそうです。L3帯域が増えたこととあわせて、AVX512になってL1/L2が相対的に不足しても力技でいけてしまうのではないかとも思えてきます。
FP Register Fileは増えていません。これはAVX512化の伏線と考えれば、データパスまるごと512bit化もあるかもしれません。期待しすぎですね。

"Better L2 cache miss bandwidth"ですが、シングルスレッドでも名目ピーク出るようになっている測定がでているようです。
"New instructions for better cache management" これなんでしたっけ???
"Wider retirement"ですが、"Wider instruction supply with deeper buffers"も含めてシングルスレッドでは使い切れない帯域があるのかもしれません。数値計算分野ではHTを使わずにシングルスレッドで最適化して演算器やキャッシュを使い切るというのが標準的なやり方な気がしますが、積極的にHTを使ったほうが性能を出せるケースも出てくるのかもしれません。
Skylakeのダイ写真
Skylakeのダイ写真が出ているようです。北森瓦版さん経由です。
北森瓦版 - “Skylake”のGen.9 Graphics Architectureの詳細

Intel Skylake Gen9 Graphics Architecture | PC Perspective
まず目に付くのはLLCのレイアウトです。SRAMセルがコアを囲むように配置されています。いかにも配線長が長くなりそうですが、逆にあえてこのようにする積極的な理由も思いつかないので電力や遅延は問題ではないということなのでしょうね。
コア内のレイアウトはここ最近のコアと基本レイアウトは変わっていません。私の興味があるのはFPUですが、これも基本レイアウトは同じようです。上下に128bitのデータパスが分かれていて、左右方向L1Dの側にあるのが演算器群、真ん中がRFではないかと想像します。
これが正しいとすると、フル512bitのデータパスを持っていることはなさそうです。あとは、512bitの演算器を持っているかですが、やっぱり見てもさっぱりわかりませんね。ただ最近のIntelはL1のB/Fは演算器の拡張に合わせて維持してきているので、その流れからすると演算器だけ512bit化はない気がしてきました。SNBの時はロードユニットを倍増して128bit幅のままロード帯域を増やしたのでした。
Skylakeファーストインプレッション
2015/8/5に開発コードSkylakeで知られていたIntelの新CPUが発売されました。私も早速動かしていますが大変よい結果を得ています。今回は主に各所で公開されている情報等から従来のマイクロアーキテクチャとの比較を見てみます。
フロントエンド
とりあえず4wayのままのようです。フェッチ帯域やMacroOps Fusion等はまだ確認していません。あんまり変わっていない気がします。
実行ユニット
instlatx64の結果がアップロードされています。
主にFPU周りの変更が目立ちます。私が使う上で気になったところを挙げます。
- div/sqrtのスループットが劇的に向上した。ついでにrcpps/rsqrtpsも高速化している。
- blendvのスループットがHaswell/Broadwellの2から1に向上した。SandyBridge/IvyBridgeと同等に戻ったことになる。
- port0/1のほとんどの命令のレイテンシが4になった。fma, mul, add/sub, cmp, min/maxなど。cvt系命令は128bitオペランドでレイテンシ2から5になっている
- add/subがport0/1両方で発行できるようになった
- fpの論理命令(addpd等)がスループット1/3で実行できるようになった
gather系命令は高速化されているはずですがまだ確認していません。128bit境界をまたぐ命令のレイテンシは3のままでした。
port0/1のレイテンシを4に統一したのは、スケジューラやデータパスの簡素化や実装によってはPRFのwriteポート数の削減等が理由として考えられます。fmaのレイテンシが5から4に改善したのはその効果かもしれません。cvt系命令はもともと演算ユニットの丸めステージのみを用いていたと考えられるので従来のport0/1でレイテンシ1+シャッフルがport5でレイテンシ1は妥当で、今回の4+1=5は無駄に遅延を挿入していることになります。
cvt系命令のレイテンシの増加とdivpdの高速化から、特別にスループットを重視する場合を除いて、doubleではrcppsからのニュートン法による収束計算は使いどころがかなり微妙になりました。AVX512ではvrcp14pdがでるのでまた変わりますが。
従来は計算ツリーによってはfmaよりもmulとaddの組み合わせの方がレイテンシが小さくなる場合があったのですが、fmaとadd/subのレイテンシが同じになったので常にfmaでよくなりました。頭の悪いコンパイラにやさしくなりました。add/subは無駄に遅延を挿入しているので気分的にももったいないです。
hsw/brwではfmaの方がadd/subよりもスループットが高かったのでadd/subの代わりに1.0を掛けてfmaした方が速い場合がありましたが、何も考えずにadd/subすればよくなりました。一方でadd/subのレイテンシが4でスループット1/2になったので典型的な総和を取るケースでは8並列にする必要があります。
fp版の論理命令はPenrynまではIntドメインで実行されていてport0/1/5でdispatchできたのですが、NehalemからはFPドメインに別に実行ユニットが設けられてドメイン間をまたぐ際のレイテンシがかからないようになった一方で、port5のみでの実行になっていました。Skylakeではスループット1/3になっており、レイテンシも1なので、ほかの命令のレイテンシとの整合性を考えると、FPドメインからはなくなった可能性があります。これが正しいとすると、FPとIntで行き来するのでレイテンシが追加されます。符号反転等ににxorを使うのは不利な場合が出てきます。まぁ最近はfmaの符号組み合わせが豊富なのであんまり使わないんですが。
メモリシステム
特にL2/L3の帯域が向上したと複数のレビューに出ています。
「Skylake-K」とはいかなるCPUなのか。「Core i7-6700K」ベンチマークで新世代マイクロアーキテクチャの実態を探る - 4Gamer.net
hsw/brwでは名目の帯域はL2で64B/cycle、L3で32B/cycleとされていました。
「Haswell」って何だ? 第4世代Coreプロセッサが採用するアーキテクチャのポイントを一気に押さえよう - 4Gamer.net
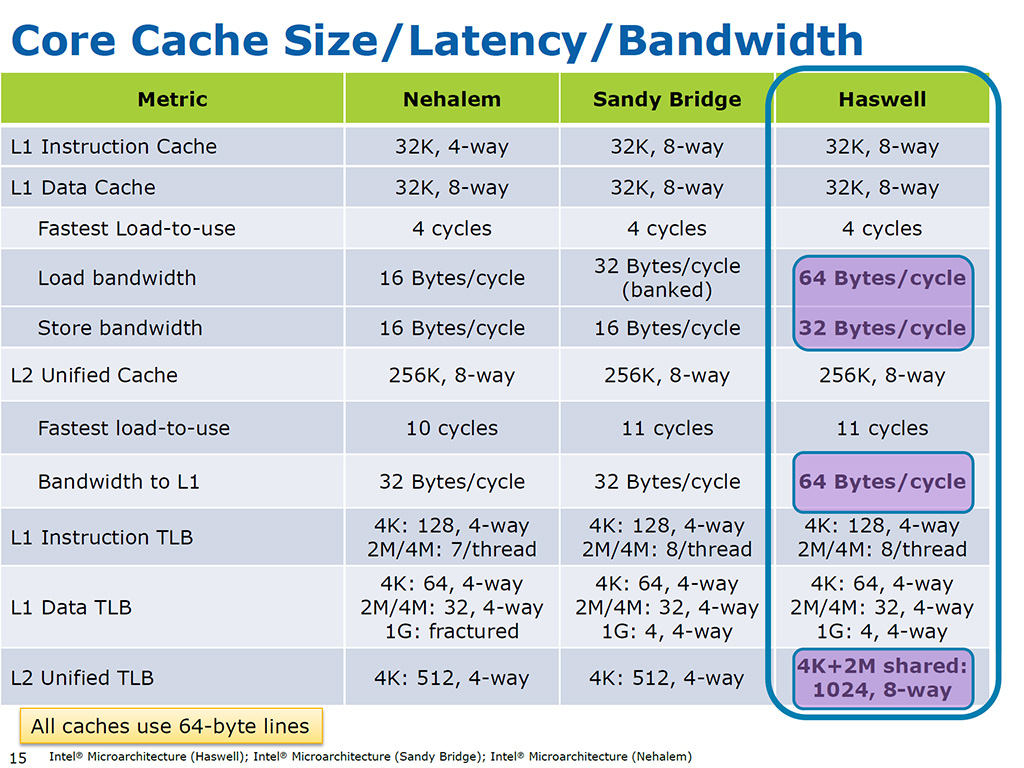
実測ではこの半分程度しかでておらず、いろいろなアクセスパターンを調べましたが、私には原因はわかりませんでした。Skylakeでは従来あった何らかのボトルネックが解消されて名目のピーク帯域に近づいたと考えるべきだと思います。
測定はしていませんが、いくつかのベンチマーク結果を見ると、ストアフォワードが改善している気がします。
FPU周りの変更やキャッシュ帯域の改善はAVX512への布石と考えたいですね。
マイクロアーキテクチャに関しては今度のIDFでなんらか解説があると思います。
ダイ写真が出れば512bit演算器をもっているがdisableされているかどうかがわかるかもしれません。最近のCPUの規模からすると演算器はゴミみたいに小さいので判別は難しいと思いますが。
追記 2015/08/23
L3のロード帯域は名目でhsw/brwの倍の64B/cycleになっているようです。さらにシングルスレッドでもL1~L3までほぼ名目ピークに近いロード帯域を発揮できるようで驚異的な向上です。Haswell-EX以降のリング+LLCに関してはまたどこかで書きたいと思います。
Skylakeの改良点を予想する~スケジューラ
前回はフロントエンドについて書いたので今日はスケジューラまわりを予想してみる。
最近のIntelのメインストリームCPUは一貫して4 wayのRSを持っている。もともとはP6で導入された3 wayのRSがCore2で4 wayに拡張されたものである。P6系のマイクロアーキテクチャでは、すべての命令を単一のRSからすべての実行ポートにDisatchするマイクロアーキテクチャとなっている。これに対し、例えばAMDのK10までのマイクロアーキテクチャではひとつの実行ポートに対しそれぞれ1つのRSを持つ分散RSもある。分散RSの欠点は、uOpsをRSにIssueする時点で実行ポートが決定してしまうため、Dispatch時に実行ポートの融通ができなくなってしまうことである。一方で単一RSの欠点は実装コストである。n wayのRSは任意のnエントリを抜いて全体を詰めるデータ構造となっているが、この実装コストはO(n^3)である。このためway数の多いRSの実装は現実的でない。
この問題に対して、いくつかの手法が考え出されている。一つはRSのクラスタ化である。例えばn wayのRSをn/2 wayのRS2つに分割すれば実装コストは1/4ですむ。一方でRSの分割は分散RSと同じ欠点、実行ポートの無駄を発生させてしまう。そこで、そもそも異なる命令種(例えばGPとFP)をDispatchするポートを別RSに割り当てることが多い。AMDのBulldozerはRSをクラスタ化した例である(RSだけではないけど)。一方でIntelは単一RSを採用し続けている。なぜだろうか?その理由を推測してみる。
一つは、そのままだが、4wayのRSの実装コストを許容していることである。もう一つはMicro Ops FusionによりRSのway数を超えるuOpの同時Dispatchを可能としていることである。
Micro Ops Fusionとはなんだったのか
Micro Ops FusionはPentium Mで導入された技術だが、Intelから実装詳細について発表はなかったんではないかと思う。たぶん。そこで参考になるのが特許である。
Patent US20040034757 - Fusion of processor micro-operations - Google Patents
読むのがめんどくさいが、以下の図がもっともよく仕組みを示していると思う。メモリオペランド命令やストア命令は2uOpsであるが、RSの1エントリにopcode1とopcode2が含まれており、opcode1の実行準備ができ実行されると結果が書き戻され、さらにopcode2の実行準備ができるとDispatchされエントリが取り除かれる。SNB以降ではPRF化されているのでsrcはPRF番号になると思われる。

肝は何かというと、たとえばメモリオペランド命令のloadとopはload後でないとopが実行できない。RSは命令順序によらず依存関係を解決するための仕組みであるので、あらかじめ依存関係がわかっているuOpsを別エントリにするのは無駄である。RSにとってMicro Ops Fusionの利点は二つある。一つは単純に消費エントリ数を削減できることである。ただしエントリ自体は大きくなる。もう一つは第一opをDispatchする際にはエントリの削除操作が必要ないことである。これによりRSのway数を超えるuOpの同時Dispatchを可能となる。
いいこと尽くめのようだが、Micro Ops Fusionはクラスタ化と組み合わせると効果が薄い。例えばGPとFPでスケジューラを分けた場合、FPのメモリオペランド命令はGPとFPのRSそれぞれに1uOpのエントリを必要としてしまう。
長くなったので続きはまた今度書こうかと思う。
Skylakeの改良点を予想する~AVX512編~
Skylake (-skl)
bmi1 avx2 smep bmi2 erms invpcid mpx rdseed adx smap
Skylake Xeon (-skx)
bmi1 avx2 smep bmi2 erms invpcid mpx avx512f avx512dq rdseed adx smap clflushopt avx512cd avx512bw avx512vl
Cannonlake (-cnl)
bmi1 avx2 smep bmi2 erms invpcid mpx avx512f avx512dq rdseed adx smap avx512ifma clflushopt avx512cd sha avx512bw avx512vl
sde上でのcpuid命令の実行結果からは、AVX512はSkylake (SKL)では使えず、Skylake Xeon (SKX)からということになっている。一般向けCPUでAVX512が使えるようになるのはCannonlake (CNL)からだが、そんな先のことはどうなるのかわからない。
ここで、Xeon DはともかくXeon E3ではAVX512が使えるのだとすれば、同じダイのCore i7とXeon E3でAVX512が使えるものと使えないものが出てくる。そして、CannonlakeはSkylakeのシュリンク版であるが、Intelの最近の傾向ではTickのターンでは大きく変更を入れない。よってSkylakeはAVX512を実行可能なハードウェアは持っているが、有効化されないのではないかと考えられる。
であれば、Skylake~ Cannonlakeではダイサイズに大きく影響を与えない程度のコストでAVX512を実装する必要がある。SandyBridgeでAVX256bitを実装した方法に準じる可能性が高い。
第一にキャッシュの帯域はAVX2仕様のHaswellのままとなる。つまりL1 load 32B/cycle x2, store 32B/cycle、L2 64B/cycleのままとなる。
第二にハイサイド側の256bitデータパスはintクラスタのものを流用する。512bit化されるのは演算器のみとなる。AVX2でintも256bit化されている。
あるいはCore2以前のように演算器を2ループまわすことで512bit分の演算を行うことも考えられる。AVX512対応はKnights Landing以降のXeon Phiとの互換性をとることが主目的とすれば、スループットを増やせなくても問題ではない。そもそもAVX512はレジスタ数の増加など、512bit化以外にもメリットはないことはない。が、スループットが増えるほうに期待したい。そして、Xeon E3でもサポートされるといいな。